<figure><img src="https://rss.neurootlichnik.ru/images/069b21a2-babd-4406-a194-39cbddd51e38/0.jpg"></figure>
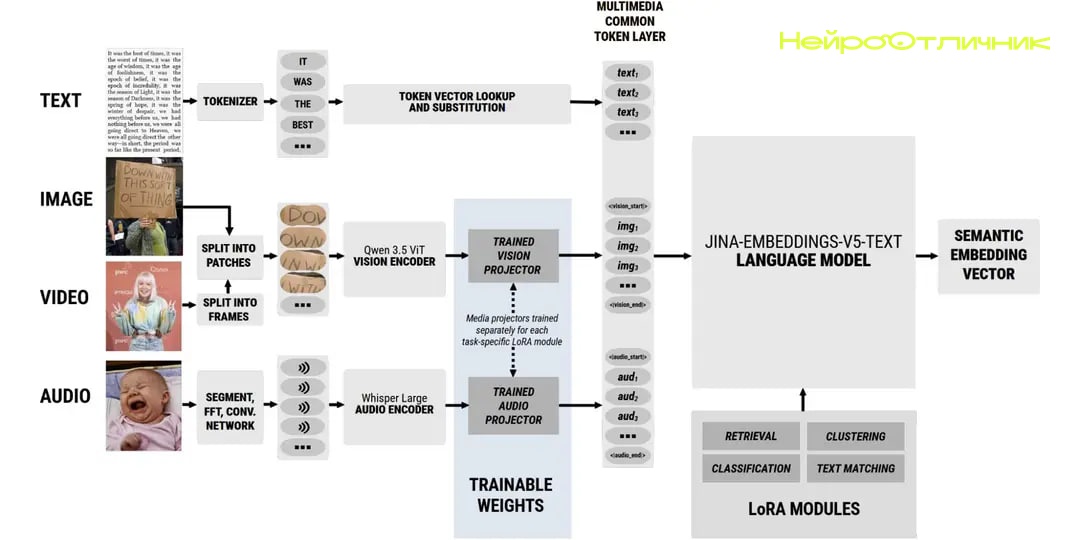
<p>Вышла новая версия мультимодальной модели <b>jina-embeddings-v5-omni</b>, которая объединяет работу с текстом, изображениями, видео и аудио в едином векторном пространстве. Это позволяет искать и анализировать разнородные данные одновременно, не разделяя их по типам.</p>
<p>Модель поддерживает почти 100 языков и может работать с текстовыми, визуальными и аудиоданными. Для пользователей, которые уже применяют <b>jina-embeddings-v5-text</b>, важна совместимость: переход на новую версию не требует переиндексации данных.</p>
<p>Важная особенность — модульная архитектура. Можно активировать только нужные компоненты: например, использовать только текст или добавить обработку изображений и аудио по мере необходимости. Это удобно для задач, где не требуется полный мультимодальный стек.</p>
<h3>Варианты модели</h3>
<p>Модель доступна на платформах HF и MS, а также имеется демо-версия для ознакомления с возможностями.</p>
<p>Благодарность за релиз — @Endorpheen.</p>