<figure><img src="https://rss.neurootlichnik.ru/images/9fd1913c-ed6f-4b28-8c5c-147169d493b2/0.jpg"></figure>
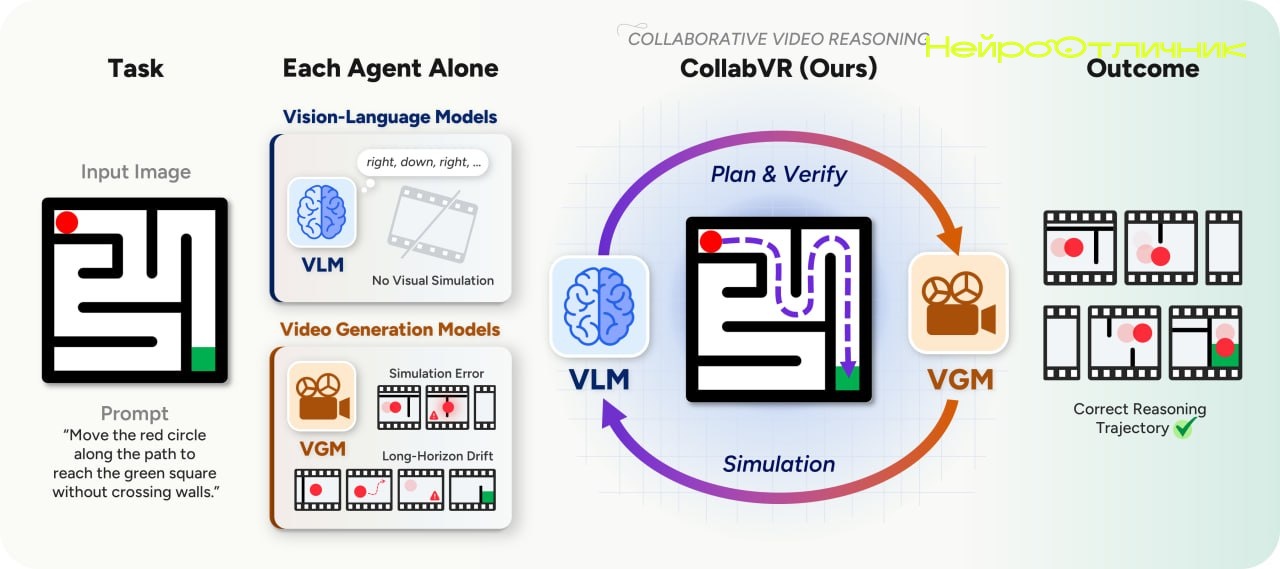
<p>В CollabVR объединили две ключевые технологии: <b>VLM</b> и <b>VGM</b>. Это не просто связка — система строит процесс так, чтобы минимизировать ошибки и дрейф при создании длинных видеороликов. Главная задача — чтобы сюжет не "уплывал" и не появлялись артефакты на середине или конце клипа.</p>
<figure><img src="https://rss.neurootlichnik.ru/images/9fd1913c-ed6f-4b28-8c5c-147169d493b2/1.jpg"></figure>
<p>Работает это так: сначала <b>VLM</b> (Vision-Language Model) планирует, что должно произойти в следующем фрагменте видео. Затем <b>VGM</b> (Video Generation Model) создает сам клип. После этого система анализирует получившийся результат и, если что-то пошло не так, корректирует дальнейшие шаги. Такой подход помогает избегать накопления ошибок и сохранять целостность истории даже в длинных роликах.</p>
<p>CollabVR уже интегрирован с <b>Veo 3.1</b> и <b>VBVR-Wan2.2</b>. Это значит, что система может работать с современными видеогенераторами, а не только с экспериментальными решениями. Гитхаб-репозиторий пока не открыт, но команда обещает его опубликовать.</p>
<p>Система особенно полезна для задач, где требуется последовательная генерация длинных видео — например, при создании обучающих роликов, анимаций с разветвленным сюжетом или автоматизации монтажа. В таких случаях важно, чтобы каждый следующий шаг учитывал предыдущие и не "ломал" логику повествования.</p>