<figure><img src="https://rss.neurootlichnik.ru/images/f67c9c93-fc03-405f-94be-0d9ed331a41c/0.jpg"></figure>
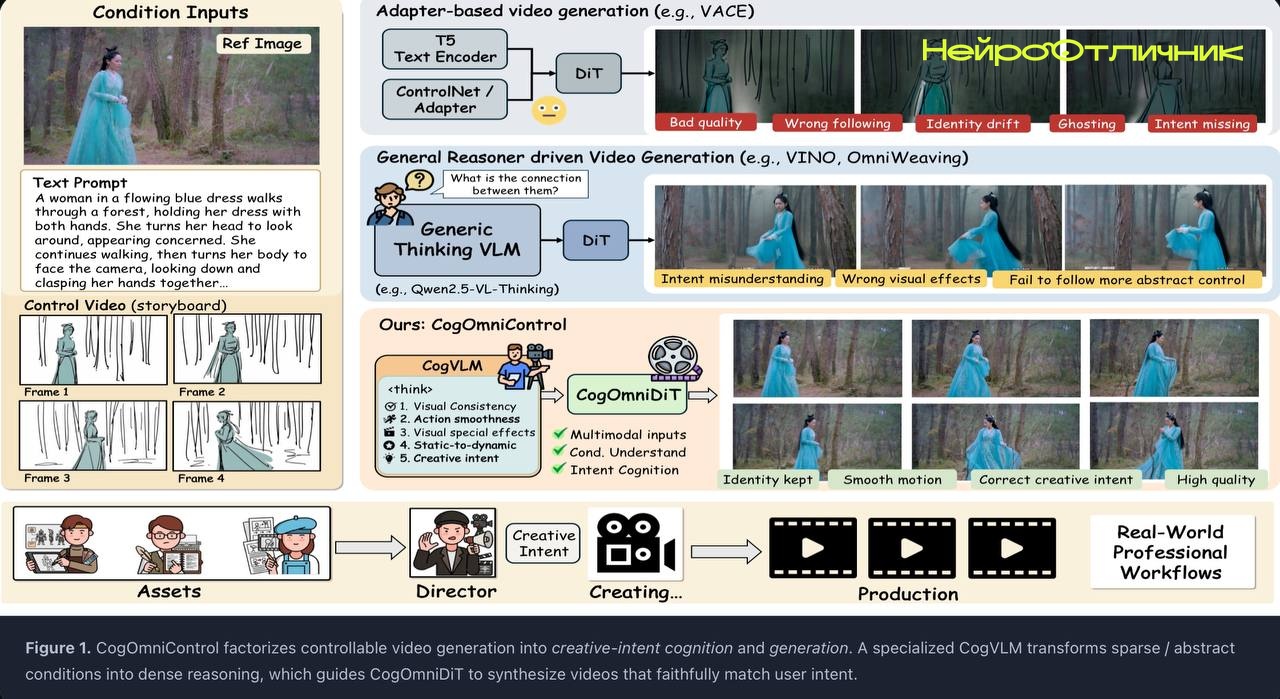
<p><b>CogOmniControl</b> — это система, которая позволяет управлять генерацией видео с помощью сложных мультимодальных подсказок. В основе лежит связка двух компонентов: <b>CogVLM</b> и CogOmniDiT. Первый анализирует запрос пользователя, даже если он абстрактный или недостаточно подробный, и превращает его в структурированные инструкции. Второй — отвечает за само создание видео, согласовывая все условия и требования через обучение с подкреплением.</p>
<p>Главная особенность — поддержка смешанных запросов: можно комбинировать текст, изображения и другие форматы, чтобы получить максимально точный результат. Система не просто реагирует на простые команды, а умеет распознавать творческое намерение пользователя и переводить его в конкретные действия для генератора.</p>
<h3>Что умеет CogOmniControl</h3>
<ul>
<li>Принимает запросы, в которых смешаны текст и изображения.</li>
<li>Генерирует видео по подсказкам разных типов, не ограничиваясь одной модальностью.</li>
<li>Точно следует сложным инструкциям, где заданы условия для разных элементов будущего видео.</li>
<li>Синхронизирует объекты и события из разных источников в едином видеоролике.</li>
</ul>
<p>Пока проект находится в ожидании релиза на GitHub (github.com/UM-Lab/CogOmniControl), но уже сейчас ясно, что <b>CogOmniControl</b> ориентирован на тех, кому важно управлять деталями генерации и добиваться точного соответствия задумке.</p>