<figure><img src="https://rss.neurootlichnik.ru/images/ed23376a-5eba-4848-9f63-c6e55ed8ca6e/0.jpg"></figure>
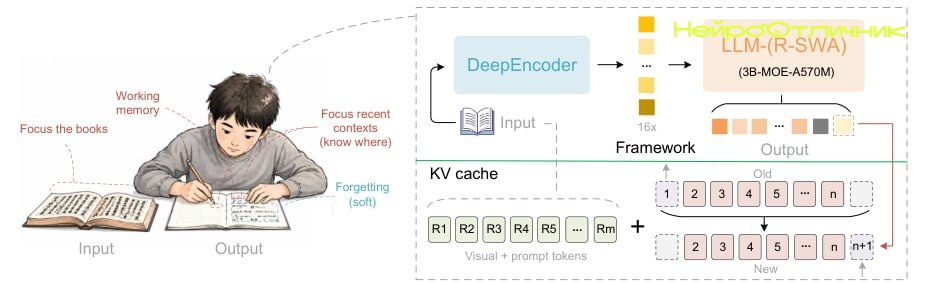
<p>Команда Baidu представила <b>Unlimited‑OCR</b> — модель, способную анализировать документы с большим объёмом информации за один проход. В отличие от многих существующих решений, здесь не требуется разбивать длинные тексты на части или подстраивать параметры под разные форматы.</p>
<p>Модель справляется как с отдельными изображениями, так и с многостраничными PDF, что особенно актуально для работы с архивами, юридическими документами или сканами книг. Её ключевая особенность — <b>однопроходная обработка</b>: весь документ анализируется сразу, без необходимости дополнительной настройки или ручного вмешательства.</p>
<h2>Где пригодится Unlimited‑OCR</h2>
<ul>
<li>Парсинг длинных договоров и отчётов, где важна целостность структуры документа.</li>
<li>Обработка разноформатных источников — от сканов до PDF, без предварительной подготовки файлов.</li>
<li>Автоматизация ввода данных из сложных документов, где стандартные OCR-системы часто дают сбои.</li>
</ul>
<p>Для разработчиков и исследователей доступен <b>репозиторий на GitHub</b>, где можно ознакомиться с кодом и интеграцией модели в собственные проекты.</p>
Нейро Отличник
www.neurootlichnik.ru